
23년 8월 부터 11월까지 주식 투자를 위한 강화학습 에이전트 프로젝트를 진행했다.
학회에서 학회원들과 힘을 합쳐 골머리 앓으며 만들었는데,
다행히 프로젝트가 성공적으로 끝났고, 마무리를 기념하여 지금까지의 스토리를 남긴다
물론 개선 사항은 더 많이 남아 보완을 하겠지만, 설령 완성한다고 해도
학생의 돈으로 실전 투자를 하는 것은 조금 미친 짓 같다
<투자는 나중에..>

1. 시작 - 금융에서 AI를 쓸 수 있을까?
현대 사회에서 가장 탐욕적이고, 불확실한 시장을 뽑으라면
부동산과 주식 시장일 것이다.
기하 브라운 운동이라고 들어봤는가?

유체같은 물질에서 입자가 불규칙적으로 움직이는 현상을
금융 공학적으로 가정한 이론이 기하 브라운 운동이라고 한다

위의 여러 파동들처럼 주가는 굉장히 불규칙적으로 움직이며,
저 많은 시뮬레이션 중 정확한 움직임을 가려내는 것이 거의 불가능하다
우리가 아는 인공지능은 모델이 가지고 있는 가중치에 따라
원하는 기대값을 뽑아내는 기술 정도로 인식되고 있다.
이미지를 분류하는 문제도, 언어를 번역하는 문제도
이 사람이 어떤 상품을 좋아할 지 맞추는 문제도
모두 다양한 경우의 수가 존재했기 때문에
현상에 대한 답을 확률의 분포로 모델링하기를 원했다.
그러면 주식도 위의 문제들처럼 인공지능으로 풀면 되지 않느냐?라고 생각할 수 있는데.
나도 이 프로젝트를 시작하기 전까지는 순수에 찬 아이처럼 YES라고 말을 했지만,
프로젝트가 끝난 시점에서 다시 대답을 해보자면
"어줍잖게 적용한다면 NO"이다.
물론 우리의 프로젝트가 형편없었다는 것은 아니지만,
그 만큼 현실의 다른 문제들보다도 더 불규칙적이고,
인간의 탐욕과 시장의 순리가 엮여있기 때문에,
몇 억개의 파라미터 가지고는 이 곳의 불확실성을 줄일 수 없다.
상상을 해보자.
천 억개의 뉴런을 가지고 있는 인간, 주식 맛깔나게 잘하는 트레이더도
실패하고 실수하는 곳이 주식 시장이다.
<고작 몇 십개의 지표와 수 억개의 파라미터로 이기는 것은 말이 안된다고 볼 수 있다>
그렇지만, 충분히 도전해볼 가치는 있다.
주식을 좀 해보면 알겠지만, 일반적으로 먹히는
차트의 패턴과 시그널이 분명히 있다.

매수와 매도 타점을 잡는 방법은 금융 공학에서 수 없이 많이 연구가 되었다.
그리고 가격의 움직임은 마냥 예상 밖으로 움직이진 않는다.
그래서 이번 프로젝트는 [불확실성 속에서 규칙을 배운다]라는 의미를 가지고 시작하게 되었다.
2. 팀 빌딩과 방향 수정
우리 팀은 총 6명으로 구성되어 있었는데,
주식 도메인 스터디 단계에서 3명이 나가버렸다.
<끝까지 같이 가고 싶었지만 참 아쉽다>
그래도 남은 3명이서 도메인 스터디와 모델 구현까지 완료해서
성공적으로 프로젝트를 끝냈음에 다행이라고 생각한다.
역할에 대한 분담은
가장 초기에는 주가 변동에 주요한 6가지 팩터<퀄리티, 모멘텀, INDEX 등..>를 가지고
각자 팩터에 대한 모델을 개발해서 최종 모델을 구성하려고 했다.
팀원 개편이 일어난 후 6가지 팩터를 3명이서 감당하기는 리소스가 부족해
팩터 기반의 모델 접근 보다 강화학습 기반으로 접근하는 것을 생각했다.
역할 분담에 대해서 상당히 고민했는데,
모두가 강화학습에 대해서 계몽적인 지식을 가지고있지 않다보니까,
섣부르게 역할을 나누어 시작하는 것보다
모두가 같은 지식을 공유한 다음 시작하는 것이 낫다고 판단했다.
그래서 이론과 레퍼를 보면서 스터디하고
추후 파이프라인 설계를 하고 데이터와 모델링, 학습, 종목 필터링 기능 등을 나누어 개발했다.
3. 강화학습 입문
강화학습에 대한 포괄적인 스토리는 알았지만,
이게 우리의 주제랑 어떻게 융합되고 작동하는 지는 전혀 알지 못하는 상태였다.
그래서 투자 공부 말고도 강화학습 알고리즘에 대해서
깊이 이해하고 체화시키는 과정이 필요했다.
강화학습에서 가장 중요한 것은
환경과 보상을 정의하는 것이라고 보았다.
환경은 에이전트가 뛰어놀 수 있게 멍석을 깔아주는 것이고,
보상은 에이전트가 이왕 노는거 잘 놀도록 동기부여를 해주는 장치이다.
사실 우리 삶과 별 다른바는 없다.
<우리도 지구라는 환경에서 수 많은 action을 하고 보상과 패널티를 받으니까..>

러프하게 디자인하면 이런 상황이 되겠다.
이 역시 우리가 주식투자를 할 때와 비슷하게 모델링 될 것이다.
무슨 말이냐면,
1. 우리는 투자 목적<단타, 장타, 스캘핑 등>을 계획하고 차트에 진입한다
2. 목적에 맞게 적절한 범위의 차트 추세를 확인한다
3. 나름의 분석에 의해 action<매수/매도/관망>을 결정한다
4. 내일이 찾아오고 내 주식이 올랐는지 떨어졌는지 피드백 받는다
5. 1~4를 반복한다
일련의 단계를 에이전트가 수 없이 많이 고민하고
최고 수익률을 내는 전략을 스스로 학습하게 냅두는 것이다.
물론 말은 간단하게 말할 수 있지만,
막상 만들려고 보면 고려해야 할 것들이 한 두개가 아니다<ㅡ.ㅡ>
4. 마부작침
옛날에 공부를 할 땐 겉멋에 빠져서 테크니컬이 전부인줄 알았는데,
막상 까보면 아무것도 없는 경우들을 참 많이 보았고, 나도 그랬다.
그때와 같은 우를 범하지 않기 위해 좀 근본적인 공부부터 시작했다.
혁펜하임씨의 유튜브를 보고 가장 많이 공부했는데,
이 분의 유튜브를 보면 5분만 지나도 칠판을 꽉채우는 수식을 보게된다
눈으로만 보고선 이해는 해도 머리에 남진 않는다.
그래서 화이트 보드를 하나 사서 그와 똑같이 쓰면서 알고리즘을 이해했다


막상 사놓고 해보니 수식 전개도 재밌고,
이런저런 아이디어를 적으면서 노는 것도 재밌다.
<얼마 안하니 꼭 해보는 것을 추천한다>
주 마다 회의를 해야해서 갈 때마다 의미있는 수확을 해야했기 때문에
시간을 그리 넉넉하게 쓸 수 없었다.
그래도 일주일 빡집중해서 나름대로 이해는 해서 투자와 접목 시킬 수 있었다.
5. 설계
이론과 실전은 분명히 다르다.
게임에 대한 강화학습 사례만 봤지,
주식은 게임처럼 보상함수를 간단하게 줄 수도 없다.
<내가 오늘 산 주식이 나중에 얼만큼의 가치를 지닐지 어떻게 안단 말인가>
보상함수에 대한 고민은 나름대로 해봤는데,
여기서 더 디벨롭된 버전을 사용하고 있다.
제일 신경썼었던 것은 학습을 좌지우지하는 보상함수에 대한 것이였고
A2C에서 Loss에 대한 구현 이었다.
또, 이번 프로젝트에선
프레임워크를 쓰지 않고 환경과 에이전트에 대한 룰을
직접 결정하고 구현했기 때문에,
아무래도 하드코딩이 많이 들어갔던 부분도 있었다.
<자세한 사항은 깃헙에 있다>
6. 파이프라인
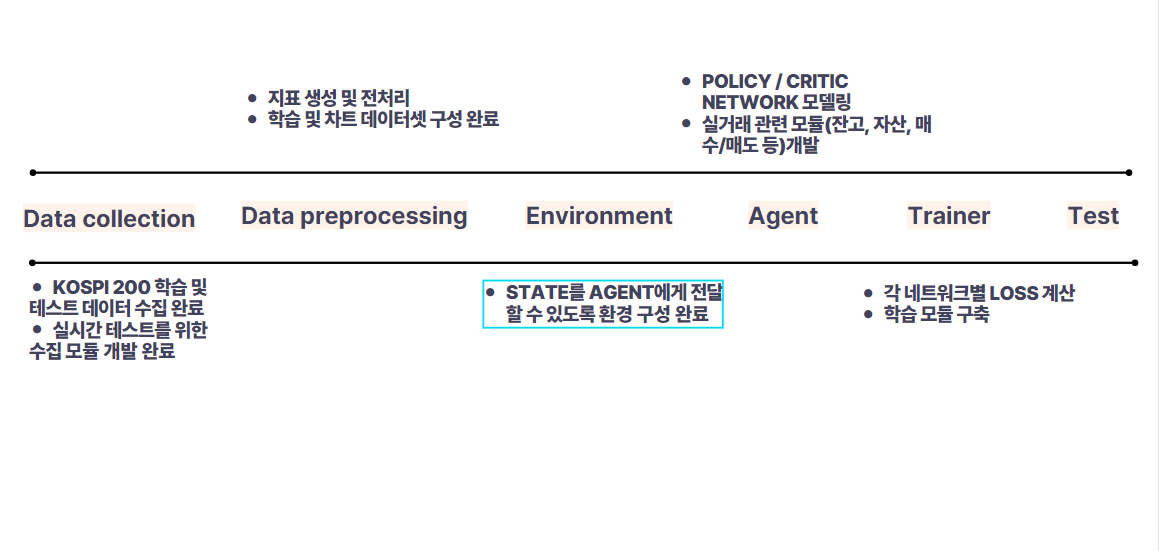
각 모듈은 크게 이렇게 구성이 되어있는데,
수집된 데이터 말고도 API와 연동해서
실시간으로 수집해서 Inference를 할 수 있게끔 기능을 개발해놓았다
전처리는 에이전트가 거래할 때 쓰는 차트데이터와
Policy에서 action을 판단하는 State 데이터<여러 지표 포함>를 구분했다
환경은 여러 종목에 대한 차트 정보를 요청에 맞게
꺼냈다 집어넣었다 할 수 있어야 하기 때문에 수작업으로 구축하였다.
에이전트는 실제 거래할 때 쓰는 기능<매수, 매도 등> 잔고와 평단가 계산 기능 등
우리가 평소에 쓰는 주요한 기능들을 넣어놓고 Policy와 Critic을 에이전트에 이식해주었다
학습과 테스트는 앞선 전체 플로우를 모두 돌릴 수 있도록
Running하는 모듈이 되겠다
구현은 크게 기능별로 분절해서 개발을 완료했다.
7. 트러블 슈팅
처음에 만든 버전은 여러 이슈가 있었다.
가장 크게 LSTM으로 이루어진 Policy Network의
Gradient Exploding으로 하나의 액션으로만 수렴하게 되는 문제.
Q-Learning 알고리즘과 똑같이 Random action을 Epsilon으로
강제하여 지정을 해줘야 할까에 대한 의문이 있었다.
먼저 Gradient Exploding은 가장 기본적으로
Clipping으로 업데이트되는 그라디언트 크기를 제어를 해줬고
이전에 가중치 초기화에 대해서 연구할 때
RNN 계열의 모델에서 Orthogonal initialization은
weight vector가 업데이트 될 때 그 크기를 결정하는
벡터의 고유값이 1에 가깝게 유지가 되기 때문에 효과적이라는 것을 알고 있어서 적용했다


왼쪽은 아무런 조치도 안한 버전 / 오른쪽은 두 가지 조치를 한 버전이다.
에이전트가 액션을 하면서 특정 액션에 대한 보상을 받게되어
해당 액션에 대한 확률을 조정하는 과정에서 기울기가 너무 크다보니
몇 스텝 가지 않아 관망 액션으로 일관하는 모습을 개선했다.

두번째는 Softmax Scaling인데,
기본적인 원리는 Policy Network의 마지막 Hidden state에
똑같은 상수를 나누어주고 Softmax를 통과시키면,
액션의 확률 분포가 평탄화되어<빨간색> 나온다는 아이디어가 되겠다.
다른 프로젝트에선 안쓰던 잡기술이라고 할 수 있는데,
이렇게 함으로써 모델이 Random action을 샘플링할 수 있도록 유도하게 되고
결과적으로 더 다양한 경험을 할 수 있게된다
8. 결과
결과는 학습하는 방식에 따라서 크게 달라졌다.
첫번째 버전은 10개의 종목에 대해 200 에피소드씩 진행했는데,
Test 때 거래를 아예하지 않는 트러블 슈팅되었던 이슈가 또 발생했다.


물론 모든 종목에서 거래를 하지 않는 것은 아니고 왼쪽처럼
저점에서 사고 고점에서 분할매도하는 좋은 그림도 볼 수 있다.

더불어 생긴 문제는 Test set과 Validation의 결과가 일관성이 부족하다는 것.
물론 Test는 모든 학습이 끝난 뒤라 엄연히 다른 파라미터를 쓰겠지만,
Valid에선 잘 버는데 Test에선 못버는 것이 문제라고 생각했다.
모델의 문제라기 보단...
학습하는 방식에 대한 문제라는 생각이 들었다.
위 실험에선 전체 에피소드를 2000번 가져갔는데,
이후 실험에선 에피소드를 2배로 늘리고
여러 종목에 대한 state를 학습하는 것이
더 일반화된 모델을 만들어 test set에서도
관망만 하는 에이전트가 되진 않을 것이라 기대했다.


왼쪽은 벤치마크 <buy and hold>의 수익률 5%를 이기고 27%를 번 test이다.
오른쪽은 워렌버핏 전성기때도 돈 못버는 차트인데, 손해는 봤지만 벤치마크보다
손실회피를 잘했다고 평가할 수 있다.
전 버전의 학습 방법과 비교했을 때
10개 종목에 대해 1~2개 종목에서 수익을 봤던 케이스와 달리
200개 종목에서 90개 가까운 종목에서 수익을 냈다.
9. 소감
아직 더 많은 스토리가 있는데,
너무 장문이 되어서 이쯤에서 끊으려한다.
자세한 건 깃헙의 발표 자료에서 볼 수 있다.
일단 가장 크게 들은 느낌은
미래 시장에 대응하기 위한 강화학습 모델은
지금보다 더 복잡한 구조와 다양한 모델을 결합한 형태가 되어야할 것이라는 것이다.
세상에서 제일 잘하는 전문 트레이더도 몇 가지 지표만 보고 거래하지 않는다.
수치로 나타내지 못하는 모종의 시그널을 캐치하는 방법을 그들은 알고 있다.
강화학습 모델은 당장 내일 CEO 리스크가 터질지 알 수가 없다.
때문에 미래 불확실성에 강건한 모델을 만들기 위해선
해당 구조에서 더 많은 정보가 반영되어야 한다는 것이다.
그럼에도 이번 프로젝트는 여러가지 의미가 있었다.
도메인은 금융투자였지만, 이번에 배운 알고리즘은 범용적으로
다양한 태스크에 쓸 수 있을 것이다.
그리고 서두에서 언급했던
[불확실성에서 규칙을 배운다는 것]을 어느정도 증명했다.
위 그래프의 매수와 매도 타점을 정확하게 짚은 여러 케이스를 보면 알 수 있다.
'Data Analysis > [Project] Financial Reinforce Agent' 카테고리의 다른 글
| 즉각 보상을 계산할 수 없는 상황일 때, 과연? (5) | 2023.11.14 |
|---|---|
| 강화학습 REINFORCE ALGORITHM의 업데이트 (3) | 2023.10.23 |
| Policy Based Reinforce Learning in Stock Trading - 정책기반 강화학습과 주식 (0) | 2023.10.22 |
| Financial Time-Series Overview<1> (0) | 2023.08.18 |
| 투자 용어 간단 정리 - 물가연동국채, 전환사채, 권리락 (1) | 2023.07.11 |