
전반부에 이어서 적는 BERT4Rec 리뷰
Embedding Layer
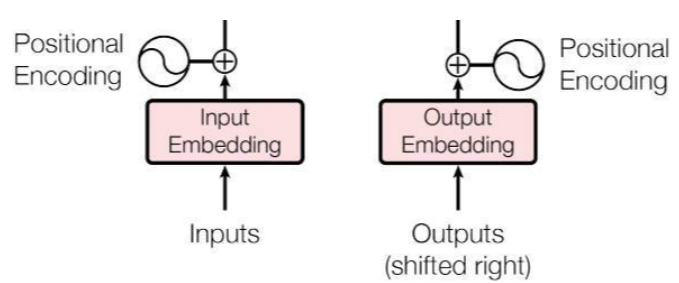
BERT 모델의 Embedding은 Input값과 Positional Encoding이 합쳐진 형태로 구성된다.
이들은 첫번째 Hidden state로 구성이되는데,
$h_{i}^{0} = v_{i} + p_{i}$ 로 두 개의 인풋이 summation된 형태이다.
Transformer는 RNN과 다르게 병렬적으로 학습하기 때문에 단어의 시퀀스를 인지할 수 없다.
때문에 각 포지션을 인지할 수 있게 Positional Encoding 작업이 추가되어야한다.
여러가지 방법으로 포지션을 할당할 수 있지만 해당 논문에서는 고정된 sinusoid 벡터가 아닌
'학습 가능한' 포지션을 부여하길 원한다. (포지션 벡터도 학습시키겠다는 뜻)
$P_{(Nxd)}$ = N(시퀀스 길이) x d(아이템 임베딩 벡터의 차원)
하지만 이 방법은 고정된 시퀀스만 취급할 수 있기때문에 특정 아이템 시퀀스만 잘라서 쓴다(Truncated Sequence)
Output Layer
Output Layer는 L개의 중첩된 Transformer Layer들이 최종적으로 뱉은 $H^{L}$ 레이어를 활용한다.
아마 최종적인 hidden layer는 이전 레이어들과의 정보를 주고받으면서 다양한 맥락을 학습했을 것이다.
이제 Prediction을 해야하는데, BERT는 시퀀스의 중간에 마스킹된 아이템을 예측하기때문에
$v_{t}$라는 masked item을 예측하기 위해선 $h_{t}^{L}$ 레이어를 활용해 예측한다.
두 개의 FFN를 통해서 예측을 하는데 한번은 GELU를 통과, 두번째는 확률값을 얻기위해 softmax함수에 통과시킨다.

$h_{t}^{L}$ : t 시점의 아이템 최종 hiddenstate
$W^{P}$ : 가중치 파라미터 행렬
$E^{T}$ : 아이템 임베딩 행렬 + 네거티브 샘플링(뒤에 설명 나옴)
$b^{P}, b^{O}$ : Bias
Model Learning
Training
기존 단방향 모델의 예측 매커니즘은 다음 아이템을 예측하는 Task로 이루어진다.
하지만 BERT는 양방향 학습이 이루어지기 때문에 즉, 타겟 아이템의 정보까지 학습하기 때문에
다음 아이템을 예측하는 Task가 부적합할 수 있다.
때문에 BERT는 MLM(Masked Language Model) 방식을 사용하는데 전반부에서 소개한 Cloze Task와 같은 방식이다.

위와 같이 특정 시퀀스의 일부를 random하게 masking하여 인위적으로 만든 빈칸을 채우는 것이다.
Loss Function은 다음과 같은 식으로 나타낼 수 있다.

$S_{u}^{'}$는 masked token이 있는 시퀀스이고 조건부확률로 해당 시퀀스가 주어졌을 때,
아이템 $v^_{m} = v_{m}^{'}$일 확률 즉, 실제 정답일 확률을 계산해야한다.
$S_{u}^{m}$ : 시퀀스 S내에 있는 masked item들의 집합
여기서는 loss function으로 'negative log liklihood' 함수를 사용했다.
<negative log likelihood>
'''
negative log likeliood : 음의 로그 가능도함수
-> log likelihood를 loss function에 맞게 마이너스 부호를 부여
likelihood : 각 target 아이템이 정답일 확률을 곱한 것
log likelihood : 곱셈으로 연결된 확률값에 log를 씌워 덧셈으로 변형한 것
-> likelihood나 log likelihood 모두 높은 값일 수록 좋다!
하지만, Gradient Descent에 의한 loss function을 만들어야하기 때문에
높을수록 좋은 log likelihood를, 낮을수록 좋은 negative log likelihood로 변환함
'''Seq2Seq의 예측 task가 가지지않은 Cloze Task의 이점은 이항적인 훈련 sample을 만들 수 있다는 것이다.

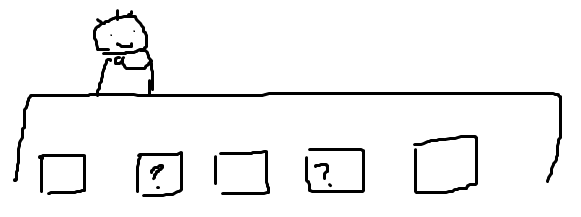
Sequential Model은 각 스텝별로 하나의 샘플밖에 맞추지 못하지만
BERT는 하나의 시퀀스에 k개의 샘플을 생성해낼 수 있다.
이를 여러 epochs 동안 학습을 시키면 더 풍부한 학습이 가능해진다
Test
Cloze task로 학습을 해도 Test는 같은 방식을 취하면 안된다.
현실에서 유저가 선택할 아이템을 보는 것은 당연히 안되기 때문이다.
때문에 논문에서는 하나의 특별한 mask token을 시퀀스의 가장 마지막 아이템에 삽입해
이 마지막 토큰을 예측하는 것으로 Test를 수행한다.(물론 Training 과정에서도 이 토큰을 가린다)
이렇게 되면 순차적으로 예측하게되는 조건을 갖출 수가 있다.
여기까지가 BERT4Rec의 작동방식이었다.
중요한 것은 Bidirectional하다는 것, MLM(Cloze Task)를 사용했다는 것이 다른 모델과 비교되는 특징을 가졌다는 것.
Discussion
원래의 BERT는 대규모의 자연어 데이터를 학습한 pre-trained 모델이다.
때문에 자연어에 기반한 여러 task(Q&A, 분류, 감정분석 등)을 Down-stream 방식으로 학습시켜서 사용해야한다.
그런데 유저-아이템-평점으로 이루어진 트랜잭션들을 자연어를 학습한 모델 기반으로 문제를 푸는 것은 이상하다.
때문에 논문에서 저자는 BERT4Rec은 종단간(end to end) 학습이 이뤄진 순차적 추천시스템이라고 말한다.
또한 기존의 BERT에서 쓰였던 Segment embedding 기법이 있는데, 이 기법도 제거했다고 한다.
-> 당연히 한 유저의 시퀀스는 하나이니 필요가 없다.
Segment Embedding : 문장과 문장을 나누는 임베딩 기법
EXPERIMENTS
Task Settings & Evaluation Metrics
Task Setting
평가방법은 LeaveOneOut을 사용했다.
train-valid-test set 구성은 test는 가장 마지막 아이템, valid는 test의 전 아이템 train은 그 전 아이템들로 하였다.
이 부분이 아마 가장 중요한 task이지 않을까 싶은데, Negative sampling이다.
데이터셋은 유저가 실제 선택한 아이템들로만 구성이된다.
예를 들어 유저 A가 사과, 토마토, 딸기를 구매했을 때, 해당 제품들의 시퀀스들로 학습을하지,
전혀 구매하지 않은 포도, 수박같은 아이템을 학습시키지 않는다.
그래서 정답을 예측할 때 엉뚱한 아이템들을 넣어서 "너 이렇게 해도 맞출 수 있어? ㅋㅋ"라고 시험을 내는 것이다.
논문에서는 100개의 negative sampling을 수행했는데 뽑는 방법도 문제다
하나도 안팔리는 물건들로만 100개를 채우면 당연히 정답을 맞출 확률이 높아지기에 두 가지 조건을 건다
1) 유저가 쓰지 않았는가?
2) 다른 유저들이 공통적으로 선호하는 것인가?
Evaluation Metric
Metric은 총 3가지를 사용했는데 Hit Ratio, NDCG, MRR이다.
해당 모델의 특성상 단 1개의 Sample에 의존해 Test를 하기 때문에, 각 k값은 1이 될 것이다.
HR@k ≈ Recall@k / MRR(mean reciprocal rank) ≈ MAP(mean average precision)
<Metric 정리>
HR@k : k개의 정답값 중에서 실제로 맞춘 갯수
Recall@k : k개의 정답값 중에서 실제 정답의 비율
MRR : 예측값들 중 정답이 몇순위에 위치했는지 선형적으로 나타낸 지표
MAP : 특정 인덱스까지의 precision 합의 평균
NDCG : relevance에 기반한 순위에 가중치를 부여한 지표
Baselines & Implementation Details
Baselines
BERT4Rec과 비교할 Baseline 모델들은 다음과 같다.
POP , BPR-MF, NCF, FPMC, GRU4Rec, GUR4Rec+, Caser, SASRec
모델링은 해당 모델이 제안된 논문과 직접 구현을 포함한다.
Parameters & others
| Hidden dimension | L2 regularizer | dropout | initialize range | optimizer |
| {16, 32, 64, 128, 256} | {1, 0.1, 0.01, 0.001,0.0001} |
{0, 0.1, 0.2 ... 0.9} | [-0.02, 0.02] | Adam |
| learning rate | β1 | β2 | Gradient clip | Layer number |
| 1e-4 | 0.9 | 0.999 | L2 norm < 5 | 2 |
| head number | maximum sequence | head dimension | mask proportion | GPU |
| 2 | 200 (ML-1m) 50 (Beauty) |
d < 32 | ρ = 0.2 (ML-1m) ρ = 0.6 (Beauty) |
GeForce GTX 1080 Ti |
논문의 마지막 부분은 실험 결과와 각 파라미터에 대한 평가로 이루어지니 다음 파트에서 다루겠다!
참고
[1] https://huidea.tistory.com/290
[2] https://heekangpark.github.io/ml-shorts/positional-encoding-vs-positional-embedding