
안녕하세요. Growth Scientist입니다.
오늘은 다중회귀분석 4번째 포스팅으로 가장 설명력이 높은 변수들을 선택하는 방법을 알려드리려고 합니다.
회귀모델에 들어갈 변수를 선정하는 것은 연구자의 몫입니다.
그 중에서도 설명력이 높고 효율적인 모델(변수의 개수 최소화)을 만드는 것도 연구자의 몫이지요.
변수들을 일일이 넣어보셔서 비교해보신 분들은 아시겠지만,
반복적이고 피곤한 작업이라 프로그램의 도움을 받아야 한다는 것을 느끼실 거예요.
그래서 오늘은 다중회귀모델의 변수입력 방법 중 동시입력방법과 단계별 입력 방법을 소개할게요.
자 그럼 시작해볼까요?
SUBJECT : 식습관을 제외한 변수 중 비만에 영향을 미치는 요인 분석
DATA : 국민건강영양조사(2019) - hn_dat
Y <- hn_dat$HE_BMI #BMI
X1 <- hn_dat$age #연령
X2 <- hn_dat$BO1;#주관적 체형인식
X3 <- hn_dat$ainc #소득
X4 <- hn_dat$BP1 #스트레스 인지율
X5 <- hn_dat$LQ_8HT #행복감
X6 <- hn_dat$educ #학력
X7 <- hn_dat$LQ_3HT #우울감
X8 <- hn_dat$BO2_1 #체중 조절 여부
X9 <- hn_dat$HE_insulin #인슐린 수치
X10 <- hn_dat$sex;X10 #성별
[ 선형회귀모델 생성 ]
동시입력방법을 소개해드리기 전에 회귀모델을 생성하는 법부터 소개해드릴게요
기본 문법 : model <- lm(Y~X1+X2+X3...,data=df)
lm은 linear model의 약자로 위와 같은 방식으로 만들어주면
Y = B0 + B1X1 + B2X2 + B3X3.. + 오차항 으로 이루어진 모델이 돼요.
model이라는 변수에 저장해주면 summary, ANOVA, plot과, 잔차, 모형 진단 등에 쓰여 꼭 필요한 작업이랍니다.

[ 동시입력방법 ]
동시입력방법은 방금 배웠답니다.
바로 위에 회귀모델 생성을 통해서요!
설명하자면, 넣고싶은 변수들을 모두 넣어서(동시에) 만든 모델이예요.
저는 선택한 변수 모두 model1이라는 곳에 넣어줄게요.

단순선형회귀는 X와 Y의 관계로 2차원 그래프를 통해 인간의 능력으로 만들고 계산할 수 있지만,
다중선형회귀는 여러가지 변수 때문에 3차원 이상의 그래프로 설명을 해야하는데 사실상 이는 거의 불가능해요.
우리는 3차원 이상의 세상을 들여다 볼 수 없기 때문이죠.
그래서 다중선형회귀분석을 할 때는 그래프를 그려보는 것보다
각 설명변수들이 Y에 미치는 영향력을 보는 것에 집중해야 해요.
그렇다면 생성된 모델에 대해서 분석해봅시다.
먼저 summary(model)을 해봅시다. summary함수는 해당 모델에 대한 요약 데이터를 제공해줘요.
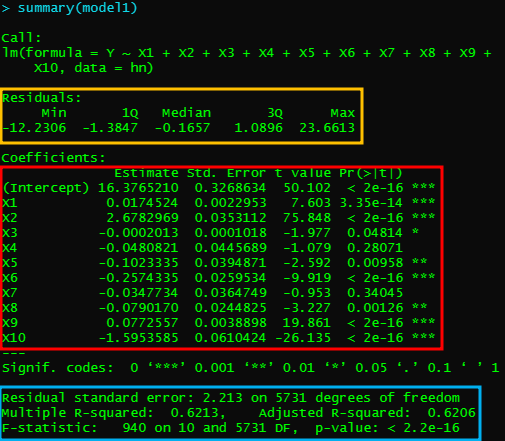
이후 포스팅에서 설명을 드리겠지만,
노란색은 잔차의 분위수, 빨간색은 회귀계수(B)들의 크기와 검정,
파란색은 결정계수(R^2)와 검정이예요.
대충 해석해보면, X4,X7은 비만도를 설명하기에 유의하지 않은 설명변수로 나오네요.
(읽는 법은 다음 포스팅 참고해주세요)
그렇다면 동시입력된 변수 중에서 X4와 X7 변수는 모델에서 제거해도 된답니다.
만약 연구 시작 전 영향력이 있을거라고 가설을 세웠던 변수라면
반응변수(Y)와의 선형성을 다시 보거나, 설명변수(X)의 조합을 조금 바꾼다면 다른 결과가 나올 수 있어요.
다중회귀모델에 구성된 설명변수들은 서로에게 영향을 끼치기 때문이예요.
[ 단계별 변수 입력 ]
단계별 변수 입력 방식은 Y를 가장 잘 설명해주는 설명변수들 순서로 투입되는 방식입니다.
연구자의 의도와 다른 변수가 들어갈 수 있는 가능성이 있죠. 백문이불여일견 한 번 봅시다.
null_model <- lm(Y~1,data=hn)
step(null_model,scope= ~ X1+X2+X3+X4+X5+X6+X7+X8+X9+X10,direction ='both',test='F')
먼저 변수들을 만들 null_model을 만들어줍니다.
그 후 step 함수를 사용하여 넣고싶은 변수들을 모두 넣습니다.
이때 direction은 'both'로 해야하는데, 유의한 변수들만 삽입이 되는 중에,
갑자기 유의하지 않은 변수(p>0.05)가 발견되면 다시 빼주는 기능을합니다.
만약 'forward'로 하게되면 유의하지 않은 변수가 발견되어도 빼주지 않습니다.
자세한 내용은, 전진 선택법, 후진 선택법을 참고하시면 될 거예요.

명령을 입력해주면, 다음과 같은 화면이 뜰거예요.
여기서 두 개의 빨간 박스를 주의깊게 봐주세요.
먼저 AIC는 AIC = 2(log-likelihood) + 2k (k=설명변수의 개수)로 표현할 수 있는데,
한마디로 회귀식의 설명력(적합도)을 가장 잘 설명해주는 모델을 찾게해주는 통계량이예요.
AIC는 낮을수록 회귀식을 잘 설명해준다고 생각하시면 편합니다.
그리고 Y~1는 Y에 대한 설명변수가 없는 모델입니다. Y = B0라고 생각하시면 돼요.
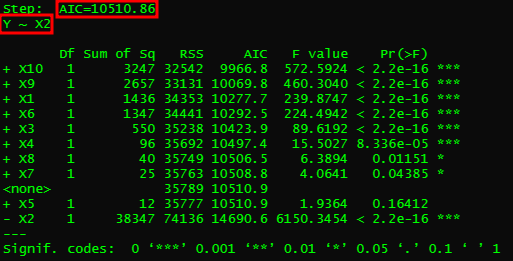
이 다음에 결과들이 위와같이 쭉 나오게 되는데,
첫번째와 비교했을 때, AIC가 약 4,000정도 낮아졌죠?
이것은 설명력이 가장 높다고 판단된 X2가 모델에 포함돼서 그래요.
이런 식으로 설명력(사진 속 F-value)가 가장 높은 순서대로 들어갑니다.

다음엔 X10이 들어왔네요. AIC는 약 500정도 줄었는데,
저는 변수들이 추가될 때, AIC 변화량을 확인하고
어떤 변수가 유의미한 설명변수인지 잠정적으로 가설을 세운답니다.
오늘은 변수 선택의 방법으로 동시입력과 step 함수를 활용한
단계별 선택 방법에 대해서 알아보았는데요.
다음엔 summary 함수를 통해 회귀모델을 해석하는 법을 알아볼게요.
그럼 BYE~
'Data Analysis > [Project] Regression With R' 카테고리의 다른 글
| [R 프로그래밍 회귀분석] ANOVA 함수와 해석 (0) | 2022.06.28 |
|---|---|
| [R 프로그래밍 회귀분석] Summary 분석 해석 (0) | 2022.06.26 |
| [R 프로그래밍 회귀분석] 탐색적데이터 분석(EDA) - 2 상관관계 분석 (0) | 2022.06.22 |
| [R 프로그래밍 회귀분석] 탐색적데이터 분석(EDA) - 1 데이터 분포 살펴보기 (0) | 2022.06.21 |
| [R 프로그래밍 실습] 데이터 불러오기 및 전처리 (0) | 2022.06.18 |